A Deep Learning model for secretly transmitting images inside audio signals.
My Bachelor’s final thesis, titled Enhancing steganography for hiding pixels inside audio signals, consisted in continuing the work by Margarita Geleta et al.. It was developed during two semesters at the Polytechnic University of Catalonia (September-January) and Dublin City University (January-May).
2023 update: Margarita Geleta and I continued this project, rerunning the experiments and obtaining some new results. Check out our paper preprint at https://arxiv.org/abs/2303.05007v2
Overview of the system
PixInWav is a project whose goal is to conceal an image inside an audio signal that will be sent, such that the former can be later retrieved by the receiver while the latter is imperceptibly distorted. This is a practice called steganography and it has been extensively studied since long ago for its many practical applications.
Traditional digital steganography often uses Least Significant Bit approaches, but new Deep Learning techniques seem to be taking over in recent years (as in many other fields). In our case we explore the particular scenario of encoding image data inside audio signals.
The system encodes the image independently of the audio using a preprocessing UNet-like neural network. The preprocessed image is then added residually to the audio spectrogram (computed using a short-time discrete cosine transform) and it is recovered through a revealing network, very similar to the first one.
The model can be trained in a self-supervised manner by comparing the distorted signals to their original counterparts. Notice that there is a tradeoff between image and audio quality, which is a common problem in steganography: in order get a higher quality recovered image one needs to add more data into the audio container, thus distorting it more. In our case we have several hyperparameters in the loss function that control this.
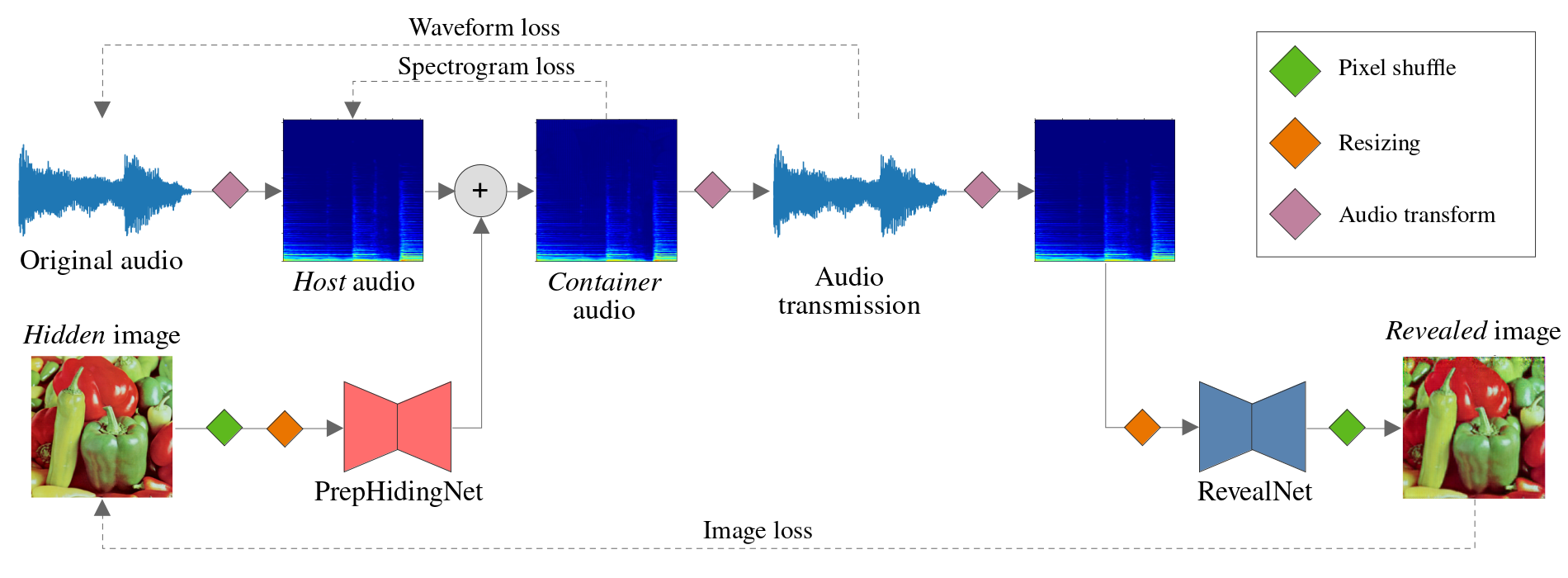
After training for several epochs, the final model was able to recover the original image from the audio with little distortion on both sides: on the image only a faint noise could be seen where the high-energy spectrogram bands used to be; the audio usually presented some constant high-frequency noise, but the overall structure was kept.
Make sure to read the original paper for all the details!
My own contributions
My work consisted mostly in trying different approaches to improve upon the original architecture. I will list here what I consider to be the main / more interesting ones.
I also did some noticeable work in the code: improving the training speed by ~10x, fixing several bugs and ultimately reimplementing a large chunk of the codebase and removing some deprecated features. This is better detailed on the project’s repo.
Short-time Fourier transform
The original work already suggested the use of this alternative transform. Together with Pau I compared the performance of the two and concluded that this new option was clearly better. As opposed to the STDCT, the STFT is a complex transform, meaning it produces both a magnitude and a phase from a single audio waveform; this offers many possibilities for using two containers instead of one. I did an extensive analysis of using either one or the two together; the image below shows one of the architectures tried for using both containers at the same time.
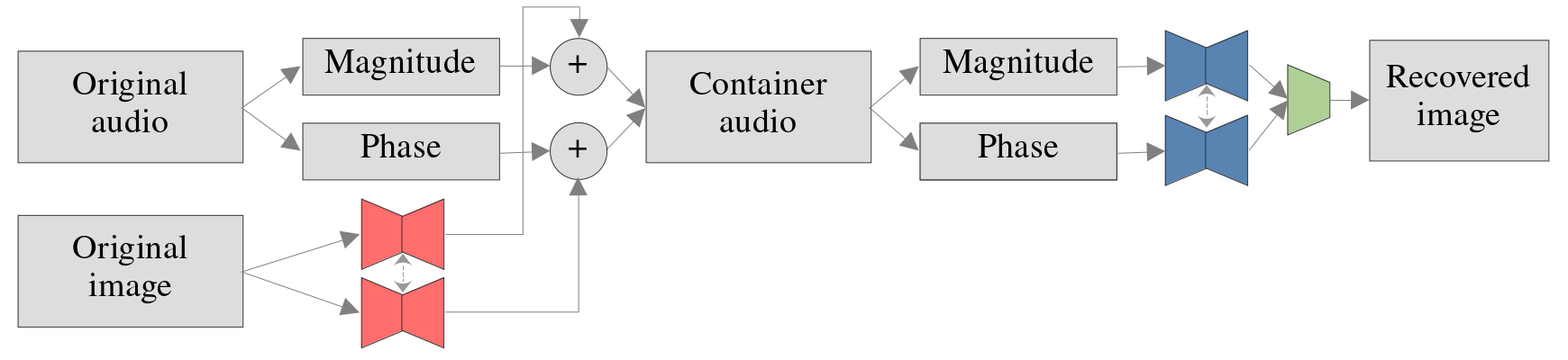
However, the phase proved to be too noisy to be used as a single container, and using two did not significantly improve upon the original baseline, so this line of work was eventually dropped.
Using other embedding methods
The original PixInWav architecture used a very inefficient operation for encoding the image into the audio, consisting mainly of stretching the former in order to make it a compatible shape. I tried several other approaches that make a more reasonable use of all the extra space that a larger container offers, mainly by replicating the image multiple times, thus adding redundancy into the signal; essentially, sending more data for free. The figure below shows the schema of one of such approaches; note that in this case the architectures of the encoder and decoder networks needed to be slightly changed.
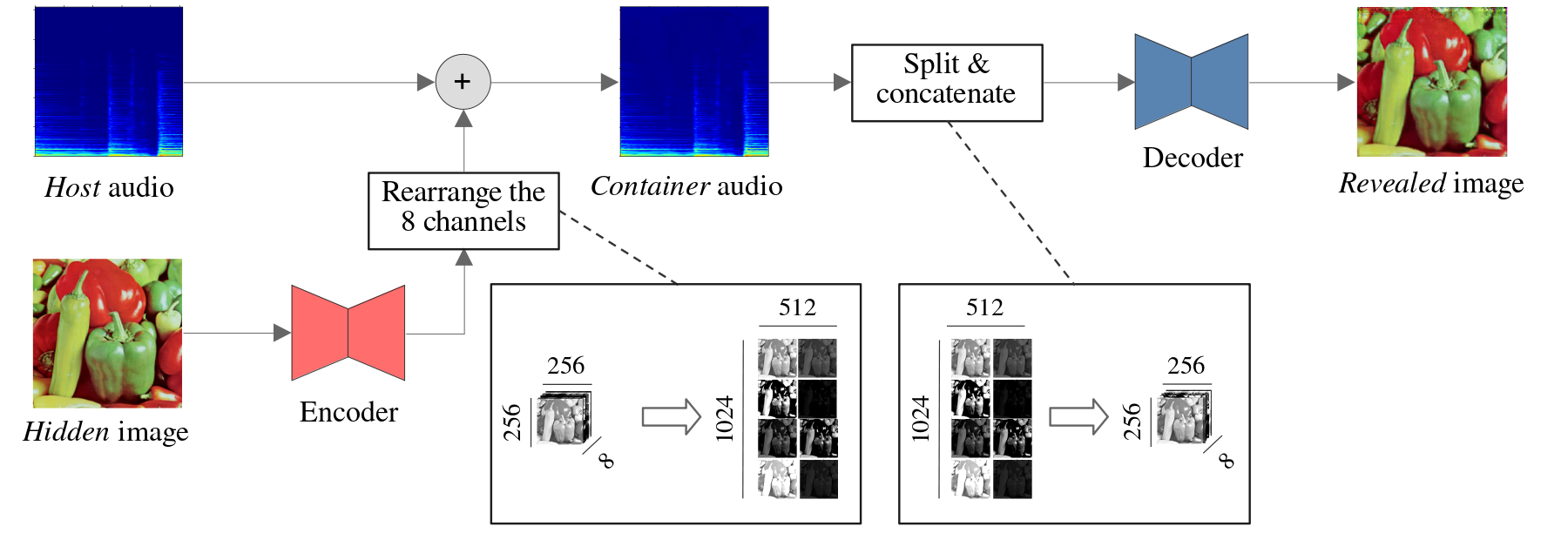
Most of the changes proposed significantly improved the performance with respect to the original baseline architecture.
Luma
PixInWav uses a pixel shuffle operation (and its corresponding pixel unshuffle on the decoder) to flatten the image from the three RGB channels into a single one, which is then processed by the encoder. However, this operation arranges the three pixels into a grid of 2x2, thus leaving a blank pixel every time. This space is simply not used in the original architecture.
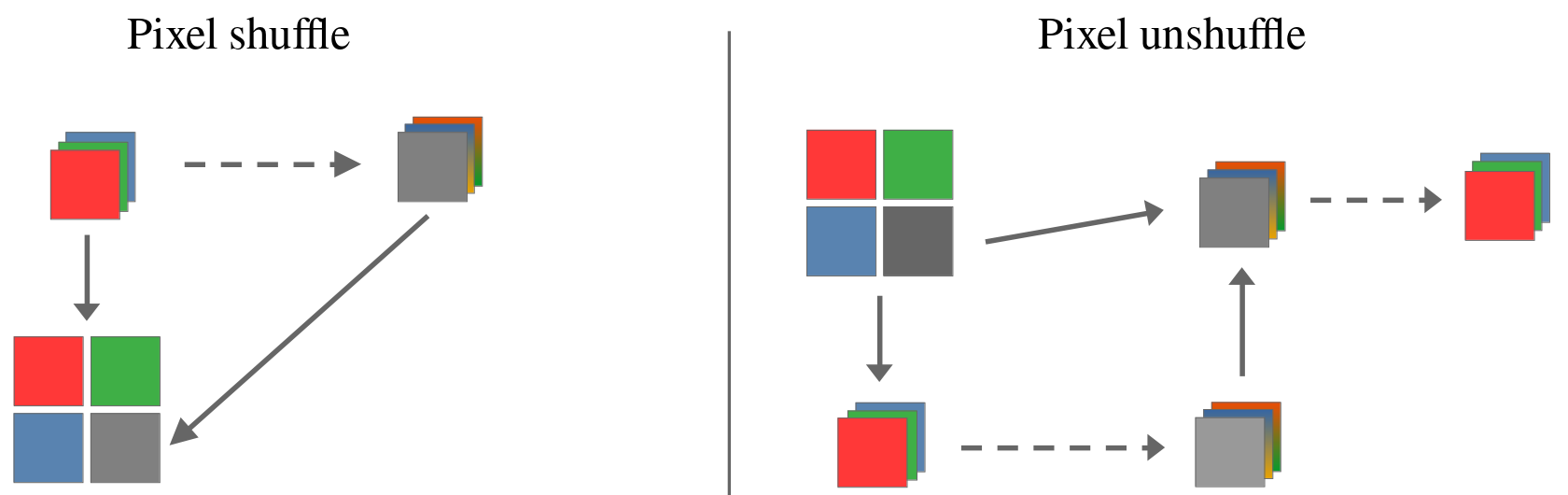
The proposed improvment consists of using this fourth component to transmit the luminance (luma) value of the pixel. This can then be used at the decoder as extra information to the RGB values and obtain a better quality image. Other than a few color space changes when doing this pixel shuffle, the architecture remains the same, meaning it is compatible with the previous improvements.
Why the luma? Because it is the single value that contains the most information about the pixel. And does it work? Yup! The performance increased significantly.
Permutation
One of my “dearest” proposed changes was the introduction of a random permutation. The figure below shows a simple schema of where such permutation would be implemented in the system.
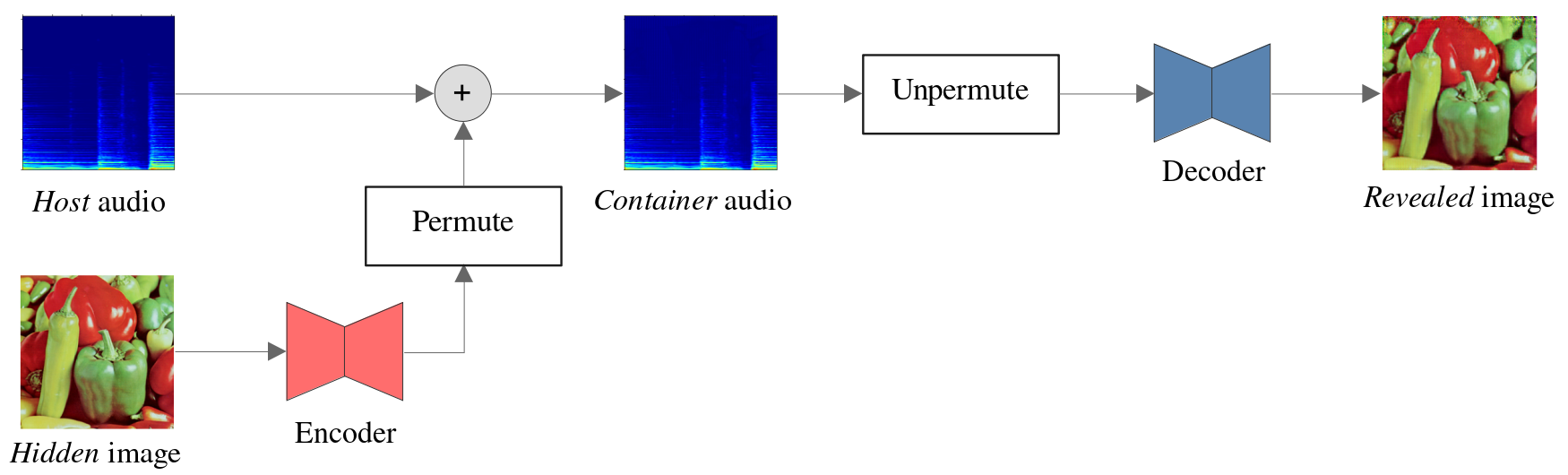
I like it specially because it is a very simple modification which I hoped would produce a great improvement in the quality of the system, by two reasons mainly:
- The image structure is broken before it is added to the audio, thus the spectrogram is not distorted by any particular pattern; instead, it would resemble the addition of white noise. Also, from a steganography perspective, the fact that the image would no longer be visible in the spectrogram (which is a problem we encountered constantly before) meant much better secrecy.
- Likewise, the audio structure is broken when the container is unpermuted, thus again the distortion in the image would be in the form of random noise uniformly distributed throughout the space, which should be easier to clean for the revealing network. The spectrogram patterns would no longer appear on the revealed image.
Unfortunately, this approach did not work at all and I had to give it up eventually. The quality of the revealed image turned out to be much poorer than before. My reasoning for this result is that permuting of the audio spectrogram, which usually has very high-energy bands and is mostly empty elsewhere, causes the revealed image to have much noise everywhere and the revealing network is unable to clean it up.
FAQ
I’ll devote this last section to tackle a few topics that people usually ask me and are not really explored in the paper.
Why transmit only images?
The type of system that we have makes images the ideal type of data to transmit, since they are 2D (same as the audio spectrogram) and convolutional neural networks do a great job processing them.
But can this be extended to using any type of data other than images then? I did have this question myself and considered doing my thesis on this subject. My idea was to use some sort of QR-code to be able to express any type of binary data as an image.
Why use the audio spectrogram instead of the waveform?
Previous work on related topics found that using the spectrogram works better (audio distortions are less noticeable). It also has the advantage that it is a 2D signal and thus the image can be easily added on top without the need for any kind of flattening.
What practical use does this have?
Reading a bit about steganography one quickly realizes the amount of potential that this field has (it’s a bit unnerving even).
But what about the specific case of sending images inside audio? One particular scenario that I like to think about is in giving radio stations the ability to send image data (say, for instance, the album cover of the song currently playing). One could develop a new protocol that somehow combines both kinds of data, but only new devices that understand it would be able to make sense of the signal, and the old radio on your grandma’s car would get confused about the new signal that it receives. However, using this system, you (with a super-new receiver) will be able to decode the image from the audio while your grandma with her chunky car radio won’t notice any change!
In general, the idea of embedding data in an audio signal is very appealing, because it can be easily sent much easily than other forms of signals. Get a speaker and a microphone and away the data goes, no need for Bluetooth anymore!
So images can really be sent through a speaker?
Unfortunately, not really. All my work assumed a noiseless transmission, where the receiver gets the exact same data that was sent, as is usually the case in digital communication.
Previously it was tried to add noise into the transmission (Gaussian, speckle and others, with varying intensities) and the system managed it quite well, with only a slight decrease in quality. However, it turns out that the distortion that is added when playing audio aloud and recording it back is much greater and much harder to model and most of the image data, encoded very subtly in the audio, is lost.
Does a longer audio mean better image quality?
In our case we always use a fixed-size audio (clipping it when necessary). The STFT parameters could be dynamically adapted to get a spectrogram of a specific size for different audio lengths.
But we have also tried adding redundancy (i.e. transmitting the same image multiple times) when using longer audios and, as expected, the image quality improves.
Links
- My written thesis
- PixInWav repository: the original code for the project that served as a baseline.
- PixInWav2 repository: my own reimplementation of the codebase.
- PixInWav paper in arxiv
- Hiding images in their spoken narratives: master thesis by Tere developed at the same time.
- Pau’s bachelor thesis: bachelor thesis by Pau developed at the same time.