End-to-end Deep Learning model that cleans the text off a meme image to obtain the original template.
This is one of those projects that are born out of boredom in a summer afternoon with friends. We felt like we should put our newly acquired Deep Learning knowledge to good use; and thus the inception of a meme-making tool.
The idea is simple: almost all meme images nowadays consist of text (usually white with a black border) on top of a photo. However, this has one serious drawback: whenever one wants to make a new meme, he/she needs to look for the original (clean) template. While there are specialized tools for this purpose, it can be hard finding the exact template, and looking for the original image of that rare meme that your friend sent sometimes feels like searching for the holy grail.
So why not make a tool that is able to remove the text out of the image so it can be reused for further meming?
That is what we did. And it works!

We coded a simple U-Net-like neural network (more on that later) that outputs a clean image of the same size as the input.
We trained it using the ImgFlip575K Memes Dataset, that has many samples of memes and their corresponding clean templates. Another approach would have been to generate the images in the training pipeline itself and train a more generic “image cleaner” in a self-supervised manner (note that there are plenty of those already available), but we wanted to use this as a coding challenge for ourselves rather than trying to achieve peak performance, and the dataset we used already did the job.
Architecture
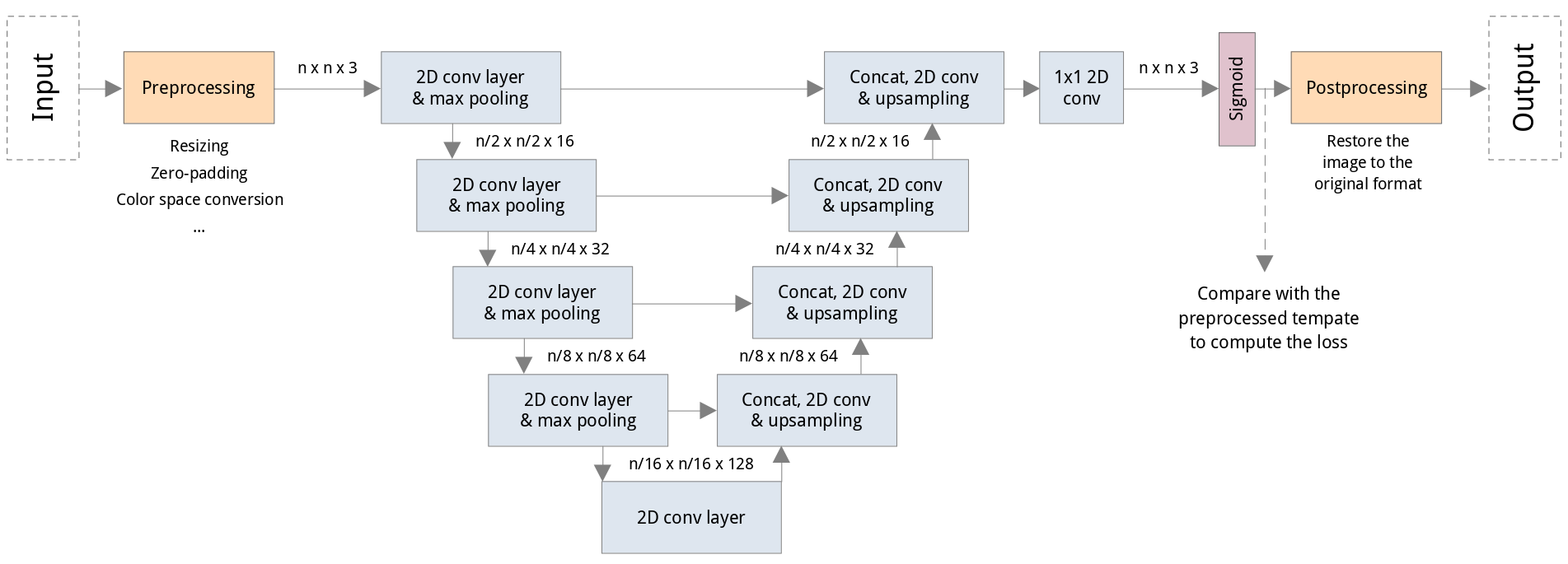
The main model is a UNet-like neural network built with PyTorch. The downsampling allows for multiresolution processing of the image, while the residual connections are useful to maintain the sharpness of the image while upsampling.
Since the model only uses 2D convolutions, the original resolution n is flexible: higher values will produce better quality images but have higher memory requirements.
The model is accompanied by pre- and post-processing scripts which can be run separately (note that the latter is not yet available). These allow to organize new data in a directory tree that the main program can read and preprocess the images to make them compatible (same shape, color space, etc.). The images are then returned to the original settings by the post-processing script.
Results
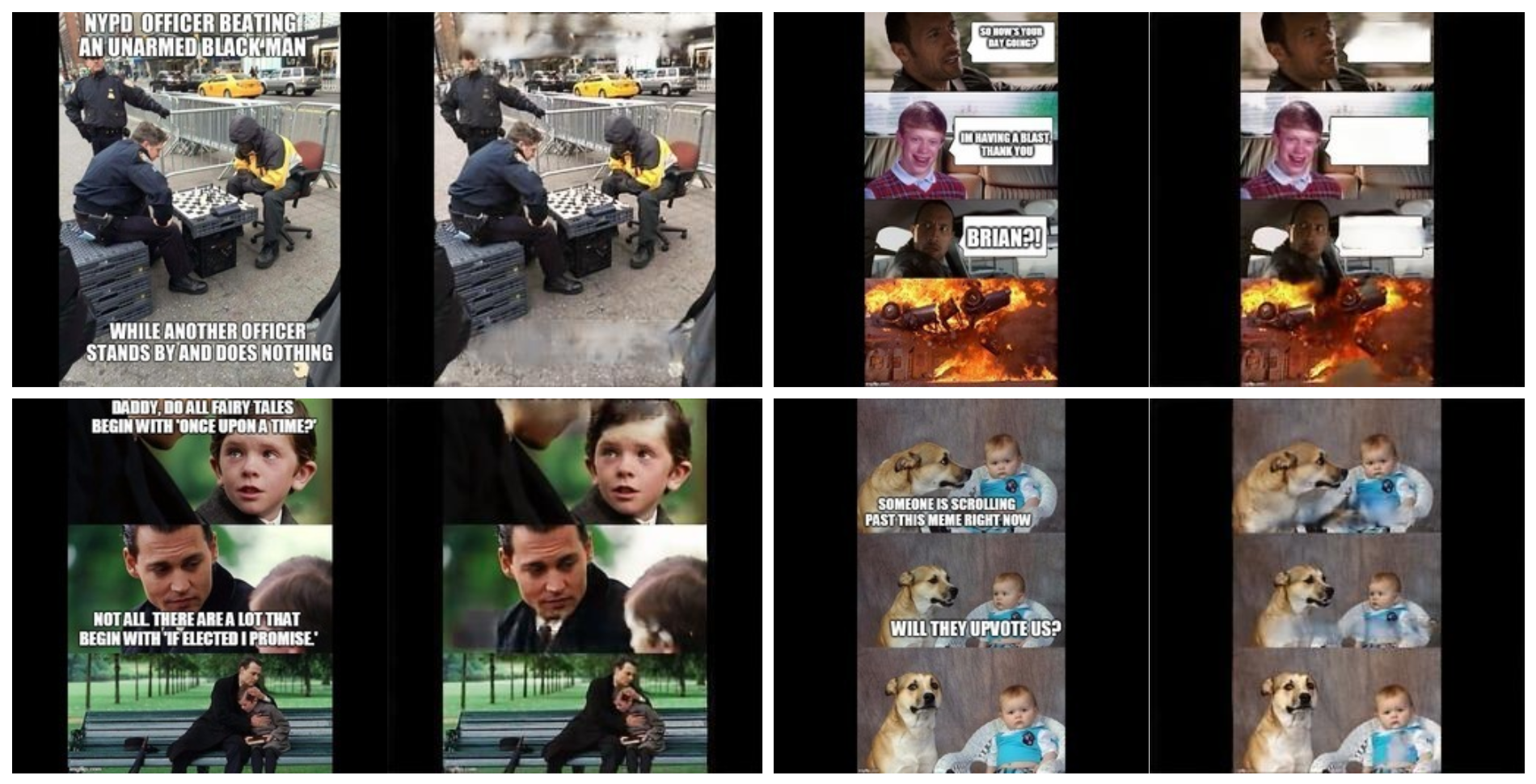
Sometimes it feels unfair how relatively easy it is to code and train a deep neural network that is able to achieve rather decent results. All the images shown here are from a preview model trained for 50 epochs on 80% of the original dataset, since we are still planning some small adjustments to the model before the final training until convergence (somewhere between 150 to 200 epochs). So I guess better results can be expected; just how much better is hard to say.
When inputting templates used during training, the model is able to remove most of the text producing almost unnoticeable distortion in the image. Some things to note are:
- The black vertical lines on the sides correspond to the zero-padding performed during pre-processing and will be removed when post-processing.
- There is some noticeable blur in the areas where the text used to be. While this would be problematic for a generic image cleaner, for our purposes this is acceptable, since any new text is probably going to go in the same place as the old.
- The slight distortion, both in sharpness and color, of the image is probably due to the model being undertrained and should be fixed when it is fully trained.

We were afraid that using a dataset limited to 100 templates would make the model overfit those images, but trying the trained model with out-of-domain data (all the examples below) also produces very decent results.